What's the most complex software in the world? Is that an OS kernel? A compiler for your favorite programming language? Maybe a web browser? To me, that would be PyTorch, a machine learning library. Now, I might be biased, since I worked on it for the past 1.5 years as part of the Quansight's PyTorch Services Team. However, I do think that people have no idea about what goes into making a modern ML library. When PyTorch 2 was announced almost a year ago, I felt it didn't receive the attention it deserved. With the PyTorch Conference on the horizon, it's time we do a recap of PyTorch's unique features.
Disclaimer: opinions are my own and not those of Quansight or other PyTorch contributors.
First of all, a programming language library can be thought of as a collection of functions. In case of PyTorch, these can be split into several groups. For example:
add, mul, div, sin)linalg_solve_triangular, linalg_cholesky)cross_entropy_loss, soft_margin_loss)fft_fft)empty, reflection_pad2d, random_, count_nonzero)mkldnn_adaptive_avg_pool2d, cudnn_batch_norm).Your typical programming language usually runs code on a CPU. Or, as with some specialized languages, this can be another dedicated device, maybe a GPU. With PyTorch being used for numeric compute, the algorithms involved can be run on modern massively parallel processors. However, there's a problem. Users might not have access to these devices. Renting hardware gets expensive quickly. Or it might just not be available, due to power saving or size constraints, like on mobile. Moreover, it's not just CPUs or GPUs these days. There are devices designed specifically for neural network compute. This brings the requirement to support the same code on a variety of devices.
PyTorch ships with several hardware backends. It supports CPUs, NVIDIA and AMD GPUs, and Apple MPS. There are also backends that are maintained out-of-tree, like Google XLA. All these devices have different architectures and instruction sets. In order to generate code for these, hardware vendors usually provide a dedicated C++ library and a compiler toolchain.
But that's not all. PyTorch is called PyTorch for a reason. It's also a Python library. The Python API is probably how the majority of users interacts with PyTorch. This means that the C++ API must match the Python one. In reality, the scope of the Python API is larger, because of pure Python functions. But users should get the best possible performance, without caring about implementation details. Additionally, there's also a need to have matching and up-to-date documentation.
There's more. Being a neural network library, PyTorch needs to compute the weights. This is done by calculating derivatives of functions mentioned earlier. Since you want to do it with respect to different arguments, there might be several implementations. These also need to be connected to the original functions, to be invoked during the backward pass. PyTorch is also dynamic. Its computational graph is generated on the fly and can be changed at run time. But users should not need to know any of this to use the library.
How do you manage this complexity?
Let's talk about code generation.
Native functions, which are implemented in C++, are declared in this tiny 15k-line file: aten/src/ATen/native/native_functions.yaml.
Here's how the division operator div is declared:
- func: div.Tensor(Tensor self, Tensor other) -> Tensor
device_check: NoCheck # TensorIterator
variants: function, method
structured_delegate: div.out
dispatch:
SparseCPU, SparseCUDA: div_sparse
ZeroTensor: div_zerotensor
NestedTensorCPU, NestedTensorCUDA: NestedTensor_div_Tensor
tags: [core, pointwise]
I mentioned before that PyTorch has a div function.
However, there are several function overloads.
As the signature tells us, this one works on two tensors and allocates a new tensor for the result.
But there are also versions that use pre-allocated storage or work on scalars.
Function overloads can be implemented differently, due to different constraints and optimizations.
For the user, it will be the same call to torch.div, no matter which argument type is passed:
In : torch.div(torch.tensor(5), torch.tensor(3))
Out: tensor(1.6667)
In : torch.div(torch.tensor(5), 3)
Out: tensor(1.6667)
In : out = torch.empty(())
# different overload, same interface
In : torch.div(torch.tensor(5), 3, out=out)
In : out
Out: tensor(1.6667)
The above shows div being called as a function, but the variants line says that it also works as a method:
In : torch.tensor(5).div(3)
Out: tensor(1.6667)
By default, the codegen creates an assert which ensures that all tensor parameters are on the same device before doing the computation. But as hinted by the comment, it's disabled here because the implementation uses TensorIterator, which provides a way to automatically parallelize operations while iterating over tensor elements.
Besides parallelism, TensorIterator also handles type promotion.
Note how the arguments above are integers, while the result is a float.
This is because div implements what's called "true division."
In general, the goal of type promotion is to implement semantics that the user would expect from an operation.
The declaration has a pointwise tag, which means that the same operation is applied to corresponding elements of two argument tensors.
But what if argument tensors have different shapes?
There are also rules for that, called broadcasting.
Here, the same data is accessed in the right-hand-side tensor when computing the output:
In : torch.tensor([[5,5,5],[5,5,5]]).div(torch.tensor([3]))
Out:
tensor([[1.6667, 1.6667, 1.6667],
[1.6667, 1.6667, 1.6667]])
Moving on, the structured_delegate line connects this to another declaration from the same file:
- func: div.out(Tensor self, Tensor other, *, Tensor(a!) out) -> Tensor(a!)
device_check: NoCheck # TensorIterator
structured: True
structured_inherits: TensorIteratorBase
dispatch:
CPU, CUDA: div_out
MPS: div_out_mps
SparseCPU, SparseCUDA: div_out_sparse_zerodim
tags: pointwise
As reflected in the signature here, this defines the out variant of the function, which accepts two tensors and modifies the provided output tensor inplace.
The structured part means that div is implemented in terms of div.out on CPU, CUDA, and MPS, unless a more specific dispatch key applies.
You can learn more about structured in the original RFC.
I'd like to point out a few things here.
First, this is where the codegen approach really shines.
Common boilerplate code can be generated automatically, which reduces bugs and overhead.
Another interesting usecase here, which will be relevant later, is how this splits code into META and IMPL parts, allowing to infer tensor output sizes without running a kernel computation.
Once the RFC was accepted, porting legacy code to structured was one of the areas Quansight helped with in 2021.
Now it's time to talk about these dispatch keys.
As mentioned above, these associate div with multiple hardware backends, as well as kernels that handle sparse tensors.
In the functional variant shown earlier, there were other examples of dispatch keys. ZeroTensor was an optimization proposal, to avoid allocating tensors full of zeros. And nested tensors is a prototype allowing to pack mismatched tensors into a single and efficient data structure, without the need of padding, while making it work as a regular tensor.
dispatch:
SparseCPU, SparseCUDA: div_sparse
ZeroTensor: div_zerotensor
NestedTensorCPU, NestedTensorCUDA: NestedTensor_div_Tensor
There are many more keys defined in c10/core/DispatchKey.h.
For instance, this is also used in the context of computing derivatives, via the Autograd key.
Wait, but there are multiple keys registered for a single operator. How does PyTorch know which implementation to call? This is part of the dynamic dispatch mechanism that PyTorch implements. Multiple things influence this. For example, the device where an input tensor is allocated. Or the current execution context. At runtime, different keys are set and stored in a bitset. When it's time to dispatch, the key with the highest priority is selected and its handler is executed. There's also a way to mask dispatch keys to bypass certain handlers, or register catch-all handlers. For more details, see this post by Edward Yang.
I've mentioned derivatives multiple times, but I haven't shown where those are defined.
There is another YAML file for those here: tools/autograd/derivatives.yaml.
Here's code for div:
- name: div.Tensor(Tensor self, Tensor other) -> Tensor
self: div_tensor_self_backward(grad, other, self.scalar_type())
other: div_tensor_other_backward(grad, self, other)
result: (self_t - other_t * result) / other_p
The cool thing about this file is that it supports inline expressions. While complex implementations can be done in C++ and referenced from here.
What's amazing to me is that it's all written in-house and is maintained by the PyTorch team. For instance, the codegen takes care of generating Python bindings, but there's more. Despite the ever-changing nature of PyTorch, the codegen and dispatcher remain the foundation of the library. To learn more about the codegen, see here.
OK, the codegen and dispatcher do a lot, but are there any disadvantages? I can't think of many. One thing that comes to mind is that "jump to definition" in your editor is often useless. So you need to know where things are located in the codebase. However, the code is well-documented and is easy to get into. Another disadvantage is that editing a header file or one of the YAML files results in a lot of things being regenerated and hence recompiled. However, this was also somewhat mitigated recently when Peter Bell, a Quansight engineer, introduced per-operator headers.
Now, let's talk about PyTorch 2.
I've spent a lot of time in the previous section talking about how things are implemented on the C++ side.
With Python being the language of the machine learning community, many people would rather use it instead of C++.
The main issue here is that pure Python implementations would be slow.
Python is an interpreted language.
Constructs like for loops are not vectorized.
You might think "no problem, I'll just call C++ functions, which are backed by kernels."
But while doing so, you'll be also paying the cost of moving data around when launching multiple kernels.
Is there a way to solve these problems?
As you might have guessed, the answer is a JIT compiler. Being just-in-time means that the user workflow doesn't change. PyTorch remains dynamic. You don't need to compile the whole model before executing. Sure, things will get compiled on first use before hitting the compiler cache, which will take some time. But you also don't compile things you don't use. And no user interaction with the compiler is required here.
This also makes standard compiler optimization techniques available to PyTorch code. Having access to more context, rather than interpreting things line-by-line, allows for kernel fusion, reducing the overhead of data transfers. This, by the way, is also one of the reasons why PyTorch has many native complex operations defined as a single kernel, rather than being a composition of simpler primitives. And this leads to operator blow up. PyTorch has roughly 2.5k operators defined on the native side. With a compiler, you could have a small set of core primitives defined instead, in terms of which the rest of operations would be implemented. All without paying the performance cost.
In order to avoid recompilation, the generated code also needs to work for as many tensor shapes as possible. One part of this is generating code that doesn't depend on concrete tensor sizes. The other is proving properties about code being executed. Does it match some other code, for which we already have a compiled kernel? Note that unlike a JavaScript JIT, we cannot bail out to the interpreter once we start executing compiled code. So this needs to be determined beforehand.
Now it's time to see how PT2 achieves all this. PyTorch's JIT compiler is called TorchDynamo. It relies on APIs added to CPython in PEP 523, which were proposed specifically for writing JIT compilers. Instead of first bothering with Python parsing, compiler writers can directly register custom callbacks to operate on Python bytecode. Dynamo extracts PyTorch operations from the Python bytecode and generates an FX Graph, or an execution trace, which can be JIT-compiled by a custom compiler backend. To avoid recompiling the same code multiple times, Dynamo implements a cache and uses guards to check if the cached value can be reused when looking at bytecode.
Dynamo architecture diagram is shown below (source):
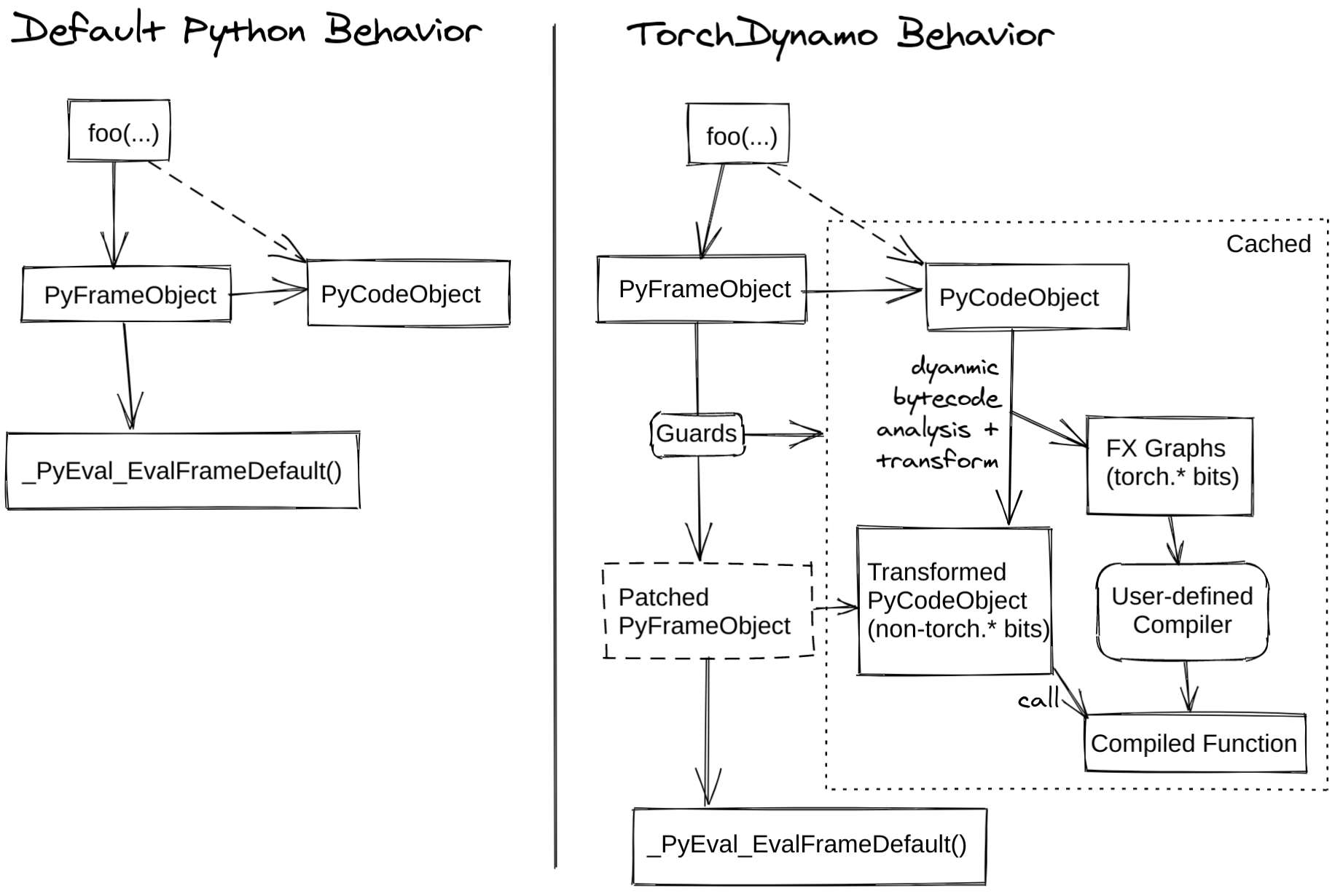
Here's a complete example of a program being optimized by Dynamo (source):
from typing import List
import torch
from torch import _dynamo as torchdynamo
def my_compiler(
gm: torch.fx.GraphModule, example_inputs: List[torch.Tensor]
):
print("my_compiler() called with FX graph:")
gm.graph.print_tabular()
return gm.forward # return a python callable
@torchdynamo.optimize(my_compiler)
def toy_example(a, b):
x = a / (torch.abs(a) + 1)
if b.sum() < 0:
b = b * -1
return x * b
for _ in range(100):
toy_example(torch.randn(10), torch.randn(10))
To make it more user-friendly, this is now available via torch.compile.
The only thing missing above is an actual compiler. During tracing, PyTorch native functions are decomposed into a set of roughly 200 core operations. These are used as the functional intermediate representation to interface with compiler backends. One such compiler is TorchInductor. It's written in Python. Inductor targets two hardware backends: CPU and CUDA. This was done from the start to make sure it can be adapted to various hardware backends. On CPU, C++/OpenMP code is generated. On GPU, it generates Triton code, a project started by Philippe Tillet, which is now being developed at OpenAI. Triton kernels are written in Python and are JIT-compiled to generate efficient machine code.
But it wasn't enough to just write a new compiler.
To trace through native code, symbolic types SymInt, SymFloat, and SymBool had to be introduced.
And, more importantly, native operators were ported to Python.
There are several layers of these Python ops.
First, there are primitives, which are defined in torch/_prims/__init__.py.
These are basic building blocks, which you cannot split further, and are used to implement other Python ops.
An example would be abs or empty_strided.
Then, there are meta functions, in torch/_meta_registrations.py.
These help infer the output tensor shape without actually doing compute.
Each meta is paired with its native function via the register_meta decorator.
You might also come across metas on the native side, but these exist for legacy reasons.
All these correspond to the Meta dispatch key.
Depending on the execution path, the dispatcher can jump between native and Python code.
There are also decompositions.
These are Python re-implementations of native code, see torch/_decomp/decompositions.py.
Decompositions bind to native code via the register_decomposition decorator.
By default, these automatically derive a meta function as well.
Also, there exist references, defined in torch/_refs/__init__.py.
When a function like torch.add is called inside torch.compile, execution will jump to the reference.
These automatically generate metas and decomps.
Additionally, these also get tested via the OpInfo framework, using the same test samples as native code.
When applicable, the same tests also run against NumPy references.
Finally, on the compiler side, there is code to produce intermediate representation in torch/_inductor/lowering.py.
For generating Triton and C++, there is pretty-printing code in torch/_inductor/codegen/triton.py and torch/_inductor/codegen/cpp.py.
Quansight contributed to many parts of this system, with patches to Dynamo, Inductor, and Triton, as well as writing new Python operations and porting native code to symbolic types.
Another thing that makes PyTorch so complex is it's size. It's huge. PyTorch core consists of various modules, which are developed independently, by different teams. Being an opensource project, contributors can range from volunteers to companies.
Besides the work mentioned earlier, Quansight is heavily involved with Sparse Tensors, by bringing support for new hardware features as well as improving performance.
There are also domain-specific libraries that build on top of PyTorch. One example would be torchvision, which our developers help maintain. We worked on things like video codecs support for vision. Also, Philip Meier gave a talk last year on the new transforms API, which utilizes a feature called Tensor Subclasses to provide a flexible interface to the user.
A few months ago, Quansight also implemented and merged NumPy support in torch.compile. By allowing TorchDynamo to trace through NumPy, users can combine code that uses NumPy and PyTorch APIs. NumPy functions that have a PyTorch equivalent will be automatically translated to PyTorch functions. For niche NumPy functions not having PyTorch equivalents, the code will just call into NumPy. Several design decisions had to be made to implement this, which you can read about in the RFC.
Quansight continues working on the Python Array API adoption. The goal of this work is to standardize functionality that exists across the current ecosystem of multidimensional array (or tensor) libraries. The APIs of these libraries are often very similar, but with enough differences to make writing code that works for all of them impossible. Last year, Quansight implemented the Python Array API within PyTorch. Once other PyData libraries update their code to use the Python Array API, they will be able to use PyTorch as their backend. Libraries that currently have no GPU support, will be able to utilize PyTorch's CUDA backend.
If you have any questions or just want to chat, you can contact me using my work or personal email address. I love meeting new people, so please get in touch and introduce yourself!
To work with Quansight, send us an email. Besides the PyTorch Services we offer, we do consulting in the areas of Data Engineering, Machine Learning, Packaging, Visualization, Algorithms, Open Source Integration, and more.
Meet us in person at the PyTorch Conference 2023! Mario Lezcano, the Head of Quansight's PyTorch team, will be giving part of the main Keynote. Travis Oliphant, the Founder and CEO of Quansight, will also be giving a Keynote: The Promise of PyTorch as a General-Purpose Array-Oriented Computational Backend. Make sure to drop by our booth!